
Advancing Human-Robot Interaction: A Multimodal Approach Combining Video & Speech Language Models With Fuzzy Logic
This project presents a multimodal human-robot interaction system integrating vision-language models (Florence 2), language interpretation (Llama 3.1), and speech recognition (Whisper) with fuzzy logic for precise control of a Dobot Magician robotic arm. Initial tests show 75% accuracy, highlighting its potential for more natural, efficient human-robot collaboration.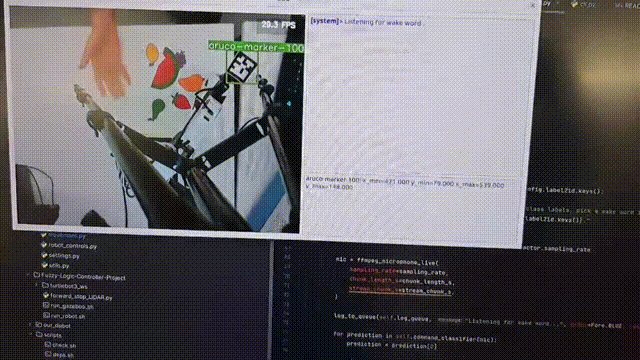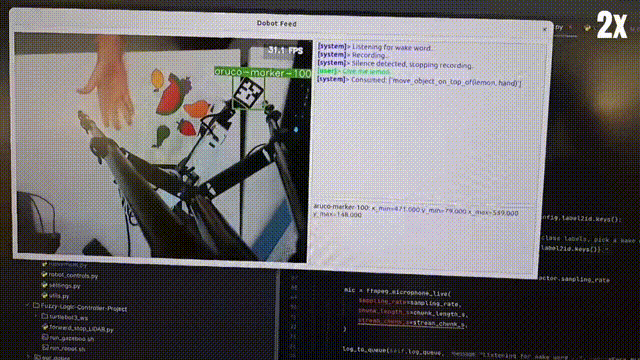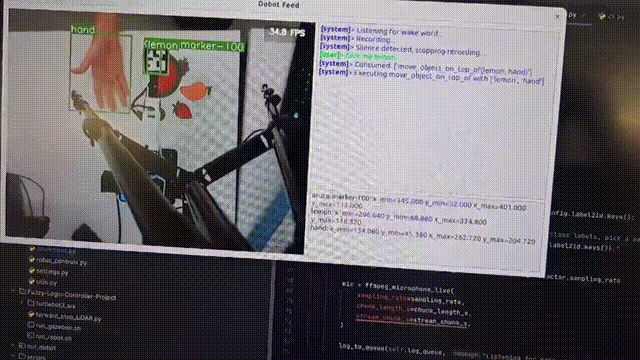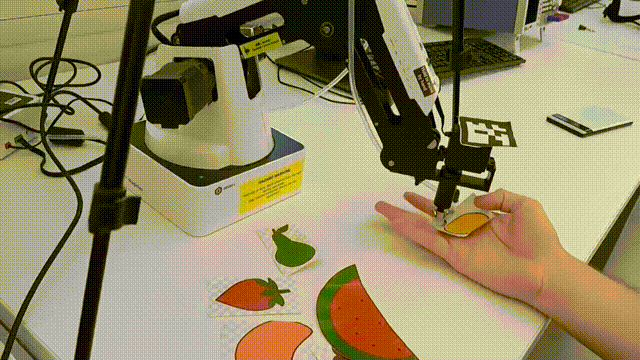

.gif)





